Banana Ripeness Classification — Custom CNN vs MobileNetV2
Frozen ImageNet benchmark vs two custom convolutional networks built from scratch, on a four-class banana ripeness dataset. The compact custom CNN beats the pretrained benchmark; the deeper residual + attention network does not — a clean, honest lesson in capacity and regularisation. CBS Machine Learning & Deep Learning final project, 2026.
Overview
A four-class image classification project (unripe / ripe / overripe / rotten) on the Roboflow Banana Ripeness v6 dataset of 13,478 photos. The brief asked for our own model rather than a black-box pretrained network, so the design splits cleanly into a benchmark we did not build (frozen MobileNetV2) and two own models trained from scratch — a compact CNN (M1) and a deeper residual + squeeze-and-excitation network (M2).
The headline result: the tiny custom CNN (M1, ~0.11M parameters) marginally outperforms the frozen MobileNetV2 benchmark (2.26M parameters) at 98.0% test accuracy, while the more sophisticated M2 underperforms both. We treat the M2 result as an honest negative finding rather than hiding it: more architecture did not help a visually constrained task.
Research question
- How accurately can a frozen ImageNet-pretrained CNN (MobileNetV2) classify banana ripeness if only a small softmax head is trained?
- Can a custom CNN trained from scratch close — or beat — that gap?
- Do residual connections and SE channel attention (M2) improve on a simple custom CNN (M1)?
The three models
Benchmark — frozen MobileNetV2
The pretrained reference: an ImageNet MobileNetV2 used as a frozen feature extractor. The backbone (inverted residuals, depthwise-separable convolutions) is not updated; only a small head — GlobalAveragePooling → Dropout 0.2 → Dense 4 → softmax — is trained. It learns the mapping ImageNet features → {unripe, ripe, overripe, rotten}, reusing generic visual knowledge rather than learning banana-specific filters.

Benchmark architecture: a frozen ImageNet MobileNetV2 backbone (purple, not updated) feeding a small trainable head (green). Only the final Dense-4 softmax learns the banana classes.
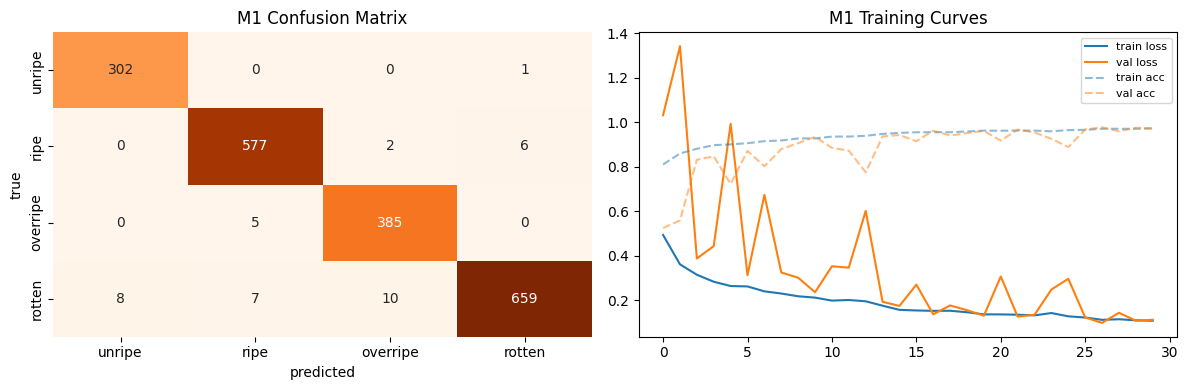
M1 — custom 3-block CNN (the best model)
The main own model: three Conv→BatchNorm→ReLU→MaxPool blocks (32 → 64 → 128 filters), then GlobalAveragePooling, Dropout 0.5, Dense 128 ReLU and a 4-way softmax. Block 1 captures edges and colour contrast, block 2 skin patches and spotting, block 3 ripeness-specific patterns; global average pooling keeps the classifier compact. It is deliberately small but well matched to a dataset of controlled, white-background images where ripeness is strongly visual.
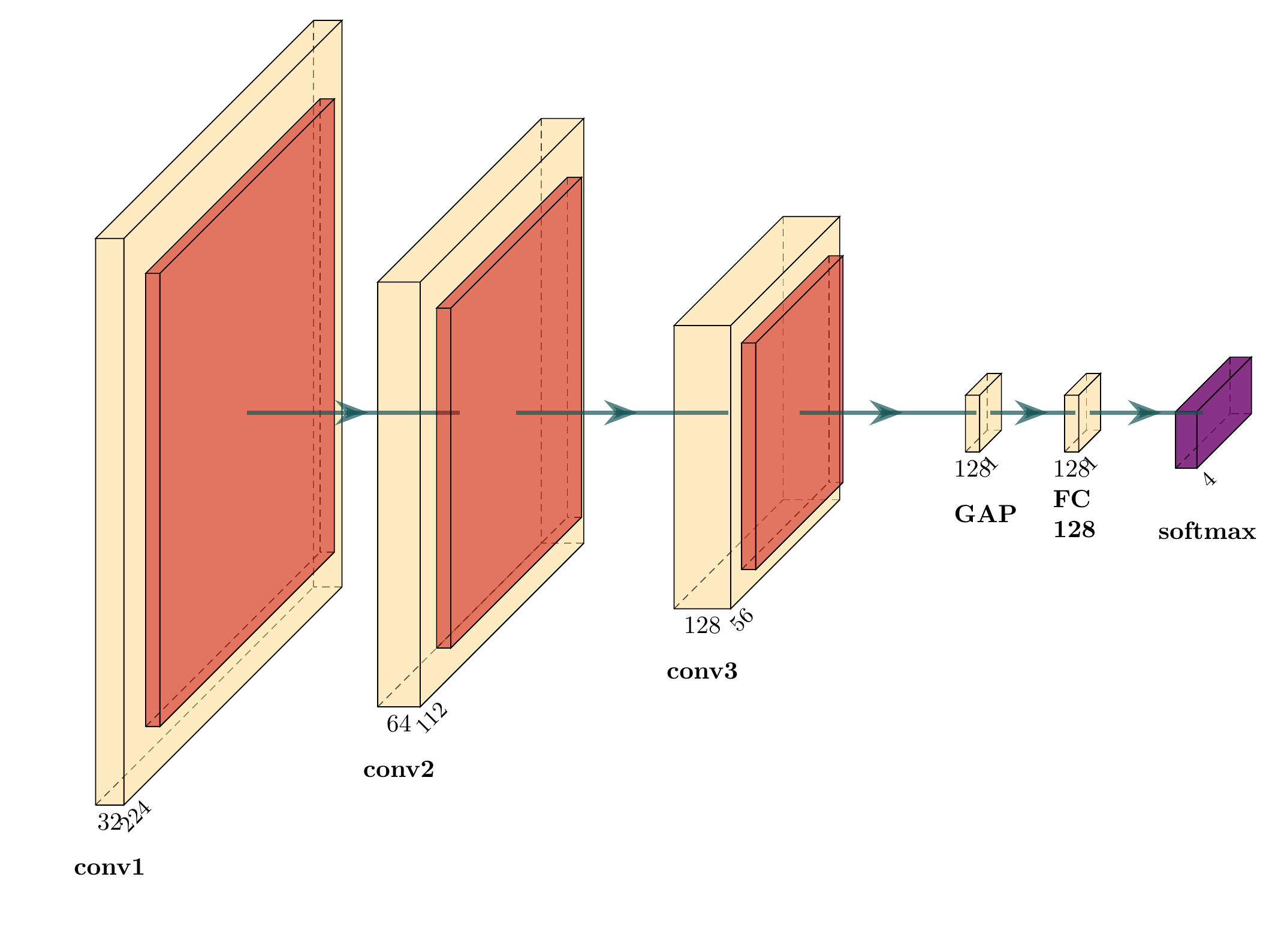
M1 architecture: three convolutional blocks (32→64→128 filters) into global average pooling and a dense softmax head — only 0.111M parameters, all trained from scratch.
M2 — residual + squeeze-and-excitation CNN
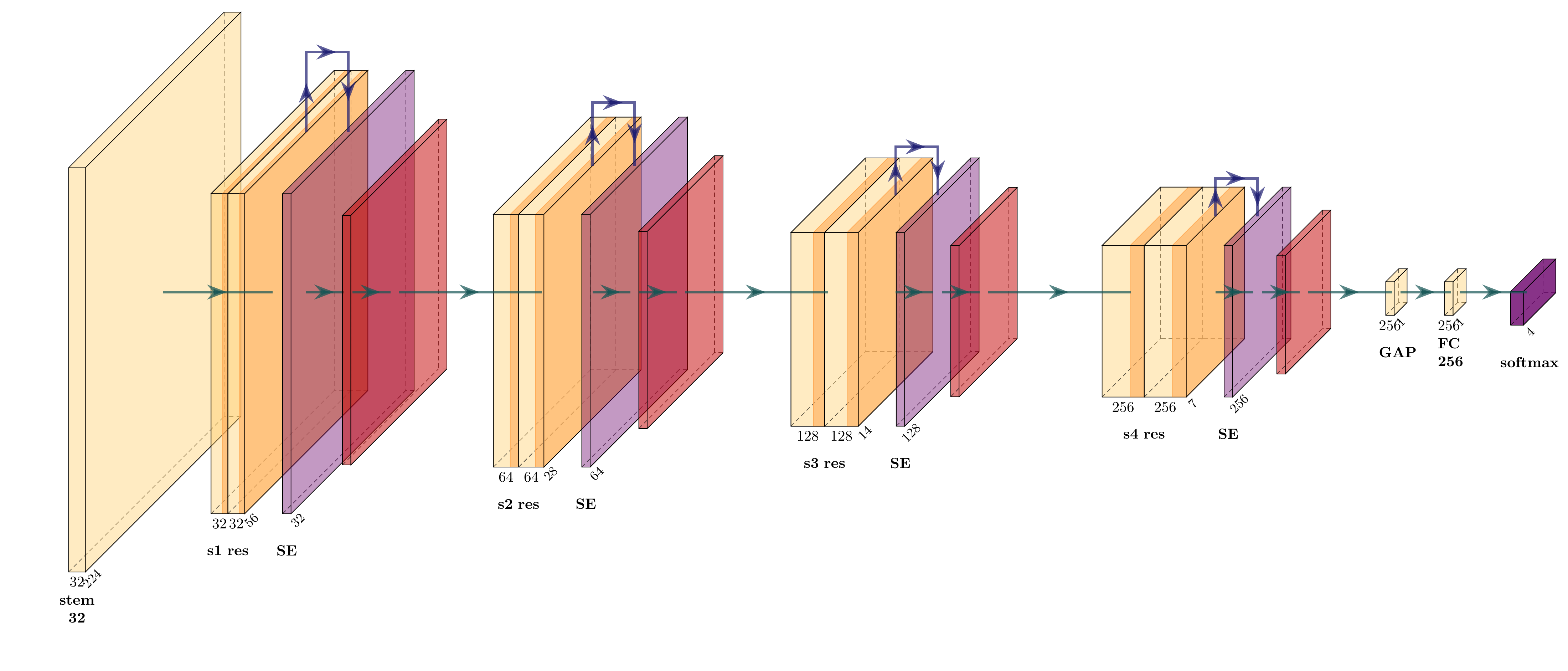
Designed after analysing M1's errors near the overripe/rotten boundary: four residual stages (32 → 64 → 128 → 256 channels) with projection shortcuts, a squeeze-and-excitation block after each stage for channel attention, and a linear-warmup → cosine-decay learning-rate schedule. A residual block learns a correction y = F(x) + x (a 1×1 projection matches dimensions when channels change); the SE block squeezes each channel by global average pooling, excites it through a small MLP s = σ(W₂ δ(W₁ z)) and rescales the feature map. The idea is defensible — but it underperformed.
M2 architecture: four residual stages with projection shortcuts (dashed) and squeeze-and-excitation channel attention (purple) after each stage, on a warmup + cosine schedule. More capacity — but worse results.
Dataset
| Property | Value |
|---|---|
| Source | Roboflow Universe Banana Ripeness v6 (CC BY 4.0) |
| Raw size | 13,478 RGB images, 416×416 px, EXIF stripped |
| Split method | pHash-aware group-stratified 70/15/15 |
| Split sizes | 9,186 train / 1,970 validation / 1,962 test |
| Leak audit | 0 / 1,962 cross-split near-duplicates |
Class counts (original): unripe 3,033 (green skin), ripe 5,460 (yellow, little spotting), overripe 3,672 (yellow with brown spots), rotten 1,313 (black/collapsed skin). The imbalance — rotten is scarcest — is handled with a class-weighted loss. 🔗 Dataset: Banana Ripeness Classification v6 on Roboflow Universe (CC BY 4.0).
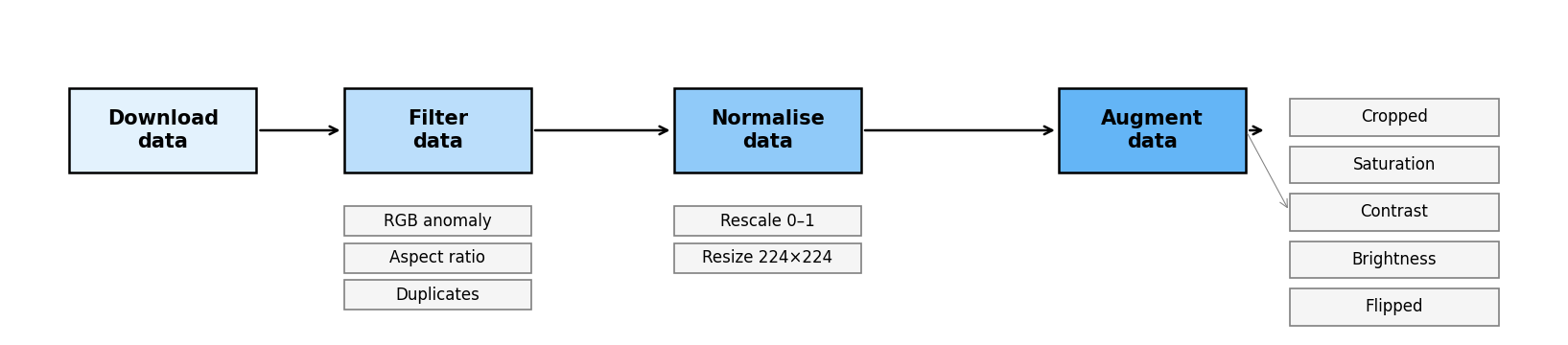
Data-preparation pipeline: from the raw Roboflow export through EXIF stripping, perceptual-hash clustering and the leak-free 70/15/15 split.
Class balance across the four ripeness stages. Rotten is the scarcest class, which is why training uses a class-weighted loss.
Methodology & technical detail
- Leak-aware split. Roboflow's offline augmentation creates near-duplicate copies under different filenames. Each image gets a 64-bit perceptual hash; images within Hamming distance ≤ 4 are clustered into connected components, and whole clusters are assigned to a single split. A naïve random split would scatter augmented twins across train/test and inflate accuracy; the final audit confirms 0 / 1,962 cross-split near-duplicates.
- Class-weighted loss. Weighted sparse categorical cross-entropy
ℒ = −w₍y₎ log p̂₍y₎with weights unripe 1.561, ripe 0.834, overripe 1.277, rotten 0.726 — baked into a custom Keras loss because the standardclass_weight=route hit a Keras 3 dtype/sample-weight bug. - Augmentation. Mild, train-only online augmentation (flip, brightness, contrast, saturation, pad + crop) via pure
tf.imageops; the evaluation set is never augmented. It is intentionally light because Roboflow already augments offline. - Training. M1: Adam, lr 1e-3, 30 epochs, Dropout 0.5 + L2. M2: Adam, peak lr 5e-4, 5-epoch warmup then cosine decay to 1e-5, early-stopping patience 7 (stopped at epoch 23).
- Evaluation. Accuracy, macro-/weighted-F1 (macro-F1 is primary — every ripeness stage matters equally), macro ROC-AUC, per-class recall, and 1,000-resample bootstrap 95% CIs on the 1,962-image test set. Grad-CAM verifies the models attend to banana skin, not background.
- Stack: Python, TensorFlow/Keras, NumPy, scikit-learn, Matplotlib; Google Colab GPU.
Results
| Model | Accuracy | Macro-F1 | Macro ROC-AUC | Params (M) | Inference ms/img |
|---|---|---|---|---|---|
| Benchmark MobileNetV2 | 0.9771 | 0.9781 | 0.9986 | 2.263 | 89.7 |
| M1 Custom CNN | 0.9801 | 0.9807 | 0.9988 | 0.111 | 84.4 |
| M2 Residual + SE CNN | 0.9297 | 0.9304 | 0.9913 | 1.319 | 85.1 |
Headline metric comparison. M1 (custom, from scratch) edges out the frozen MobileNetV2 benchmark; M2 sits visibly below both despite being the most complex network.
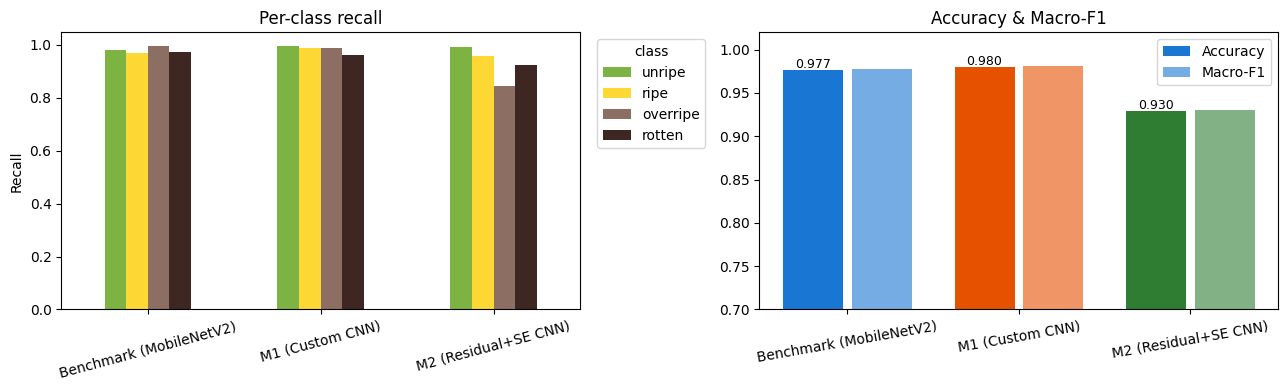
Per-class recall
M2's failure is concentrated in a single class — the overripe↔rotten boundary, where M2 made 131 errors versus M1's 37.
| Class | Benchmark | M1 | M2 |
|---|---|---|---|
| Unripe | 0.980 | 0.997 | 0.993 |
| Ripe | 0.968 | 0.986 | 0.957 |
| Overripe | 0.995 | 0.987 | 0.846 |
| Rotten | 0.974 | 0.963 | 0.925 |
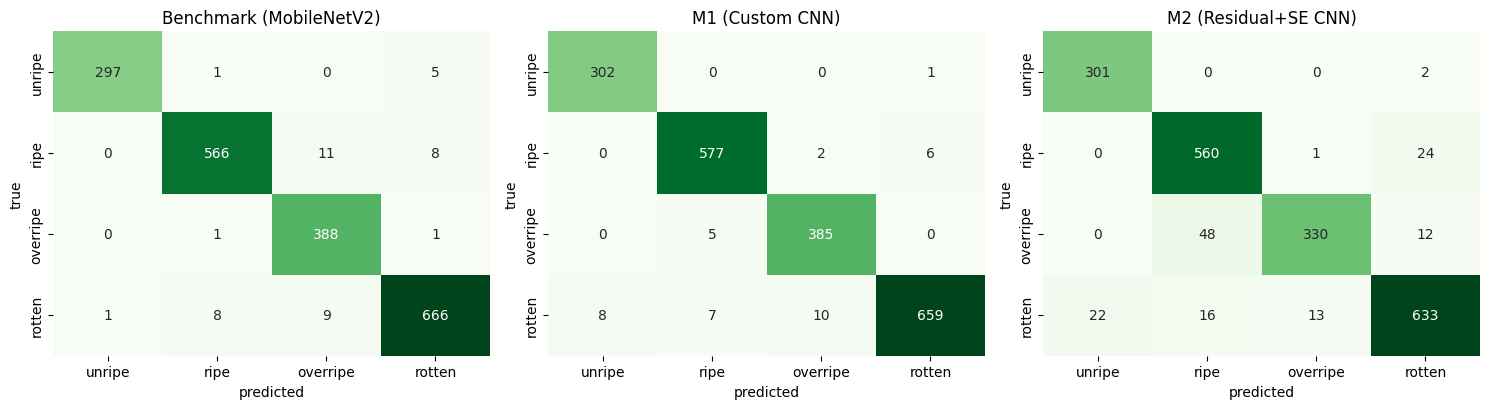
Per-class recall. Every model is near-perfect except M2 on the overripe class (0.846) — the clearest single sign of where the deeper network breaks down.
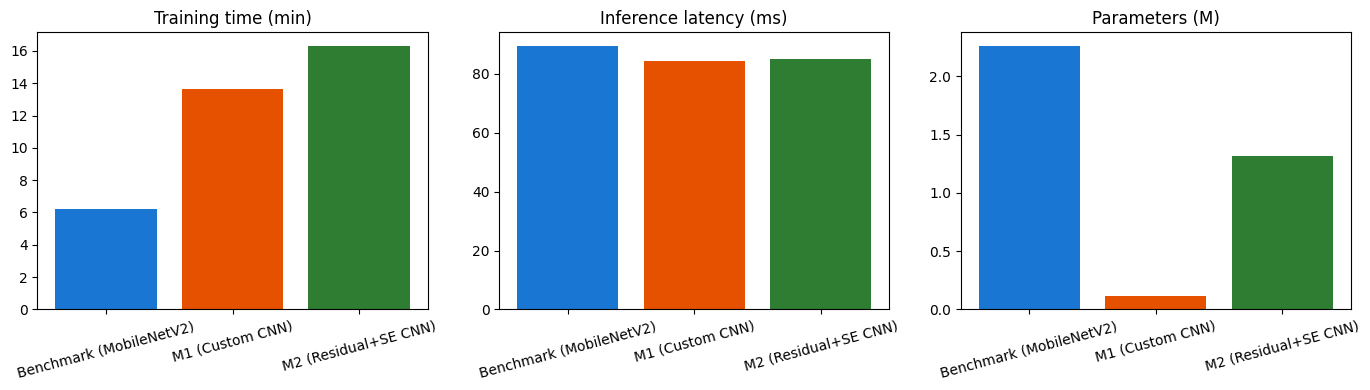
Complexity and uncertainty
| Model | Params (M) | Train (min) | Test accuracy | 95% bootstrap CI |
|---|---|---|---|---|
| Benchmark MobileNetV2 | 2.263 | 6.2 | 0.9771 | [0.9699, 0.9832] |
| M1 Custom CNN | 0.111 | 13.7 | 0.9801 | [0.9740, 0.9862] |
| M2 Residual + SE CNN | 1.319 | 16.3 | 0.9297 | [0.9185, 0.9409] |
The benchmark and M1 confidence intervals overlap, so the 0.3 pp gap is best read as within sampling noise: M1 matches a much larger pretrained model with roughly 20× fewer parameters. M2 is clearly and significantly worse. The defensible claim is modest — a compact custom CNN can match or slightly outperform a frozen pretrained benchmark on this controlled dataset — not that M1 is decisively better.
Accuracy against model size. M1 lands top-left — best accuracy at a fraction of the parameters — the project's central efficiency story.
Interpretability & error analysis
Four-class confusion matrices (kept because they pinpoint the failure): M2's off-diagonal mass concentrates on overripe being read as rotten, exactly the boundary the architecture was meant to fix.
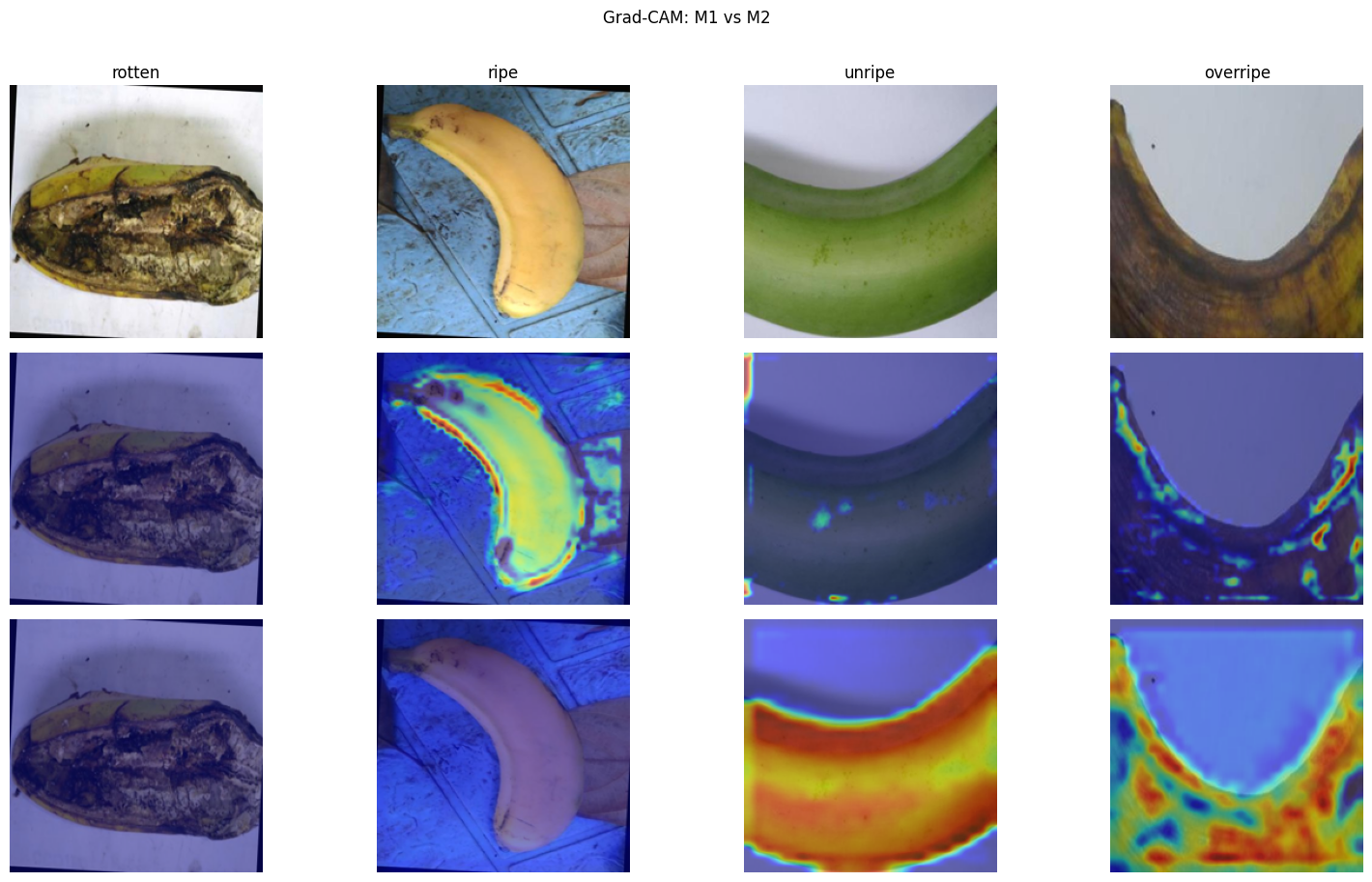
Grad-CAM heatmaps confirm the models attend to banana skin, spotting and shape rather than background — evidence the predictions are based on genuine ripeness cues. M2 likely over-focuses on dark spotting, confusing overripe with rotten.
Design decisions
- MobileNetV2 as benchmark, not primary model. The brief warned against submitting only a complex pretrained CNN, so MobileNetV2 is a frozen reference and M1/M2 are the own models — and the main result is the compact custom CNN.
- pHash-aware split to neutralise offline-augmentation leakage (0 cross-split near-duplicates).
- Custom weighted loss to handle imbalance while sidestepping the Keras 3
class_weight=bug. - M2 after M1 error analysis — residual + SE + warmup/cosine to target the overripe/rotten boundary; the negative result is reported honestly.
Engineering notes (debugging log)
- Keras 3
class_weight=caused dtype/sample-weight issues with thetf.datapipeline → replaced with a custom weighted cross-entropy. - Keras preprocessing layers in
Sequentialcaused dtype-promotion issues insidetf.data.map→ replaced with puretf.imageops. - Grad-CAM in Keras 3 doesn't cleanly expose symbolic
.input/.outputfor Sequential models → manualGradientTapeforward pass for M1, graph-based extraction for the functional M2.
Related work
The project sits between classic fruit-ripeness classification (Mazen & Nashat 2019; Saranya et al. 2022 — colour/texture are highly discriminative, motivating saturation-aware augmentation) and modern CNN transfer learning (MobileNetV2, Sandler et al. 2018; residual and SE attention, He et al. 2016 / Hu et al. 2018; Grad-CAM, Selvaraju et al. 2017). Its contribution is a leak-controlled, benchmark-disciplined comparison showing a compact custom CNN can match a frozen pretrained model — plus a negative result on architectural complexity.
Limitations and future work
- Single-source dataset with mostly controlled studio backgrounds; no external in-the-wild (shelf/warehouse) evaluation images were available.
- Ripeness is ordinal, but the models treat it as nominal — an ordinal or cost-sensitive loss could penalise overripe↔rotten confusions directly.
- Online augmentation was not ablated; future work would test lighter M2 variants and a no-augmentation baseline.
Downloads
Final report (PDF) Defence slides (PPTX) Code on GitHub Dataset (Roboflow)
Related Projects
- Traffic Sign Recognition — convolutional neural networks for multi-class image classification
- Echo Chamber Linguistics — supervised text classification, also CBS Data Science 2026
- Forecasting Danish Pharmaceutical Exports — time-series forecasting, CBS Data Science 2026