Echo Chamber Linguistics
Can the lexical content of a single YouTube comment predict the political ideology of the channel it was posted on? Five models compared on 301,536 comments — from sparse linear baselines to a fine-tuned transformer and a frontier LLM — with a cross-channel ablation that exposes how much of the "signal" is really writing style. CBS NLP final project, 2026.

Overview
A binary text-classification study (left vs right) on 301,536 English YouTube comments scraped from 7 US political channels. The question is deliberately framed around the channel's ideology, not the commenter's: the model must find signal in individual comments that may or may not align with the host's stance — and the project measures how much of any model's success is really learning channel writing style rather than ideology.
The dataset is published openly on Hugging Face as Sapek007/yt-political-comments.
Research question
Can the lexical content of a YouTube comment alone predict the political ideology of the channel it was posted on?
Pipeline
| Stage | Method | Output |
|---|---|---|
| Cleaning 1 | Row filtering | 301,536 rows |
| Cleaning 2 | Two text variants (text_clean, text_clean_baseline) | model-specific inputs |
| Split | 80/20 stratified, seed 42 | train / test |
| Ablation | Hold out one whole channel at a time | −12.6 pts F1 |
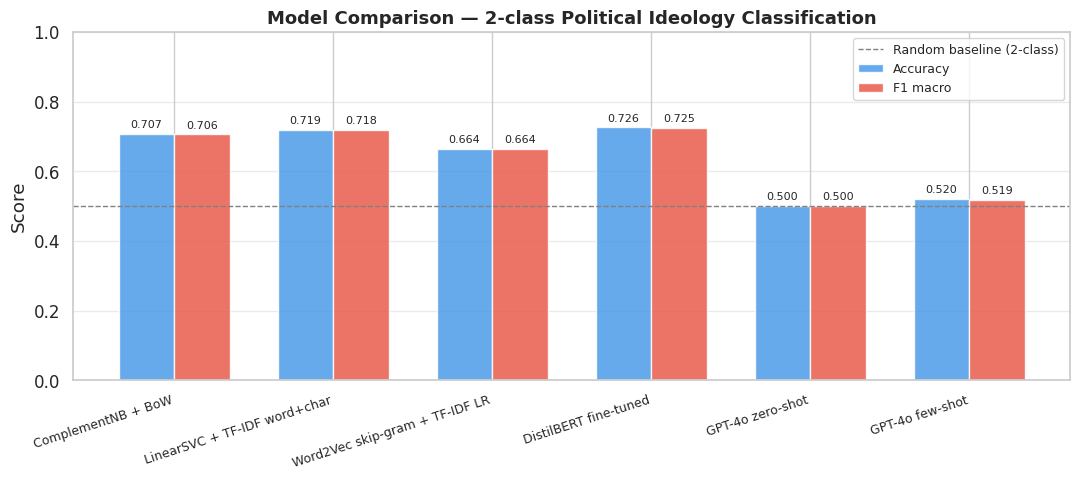
Models & results
Five models span the full spectrum from sparse linear baselines to contextual transformers and a zero-shot LLM:
| # | Model | Representation | F1 macro |
|---|---|---|---|
| 1 | Complement Naïve Bayes | Bag of Words | ≈ 0.69 |
| 2 | LinearSVC | TF-IDF (word + char n-grams) | 0.718 |
| 3 | Logistic Regression | Word2Vec embeddings | ≈ 0.66 |
| 4 | DistilBERT (fine-tuned) | Contextual transformer | 0.726 |
| 5 | GPT-4o-mini (zero/few-shot) | Frontier LLM | ≈ 0.555 |
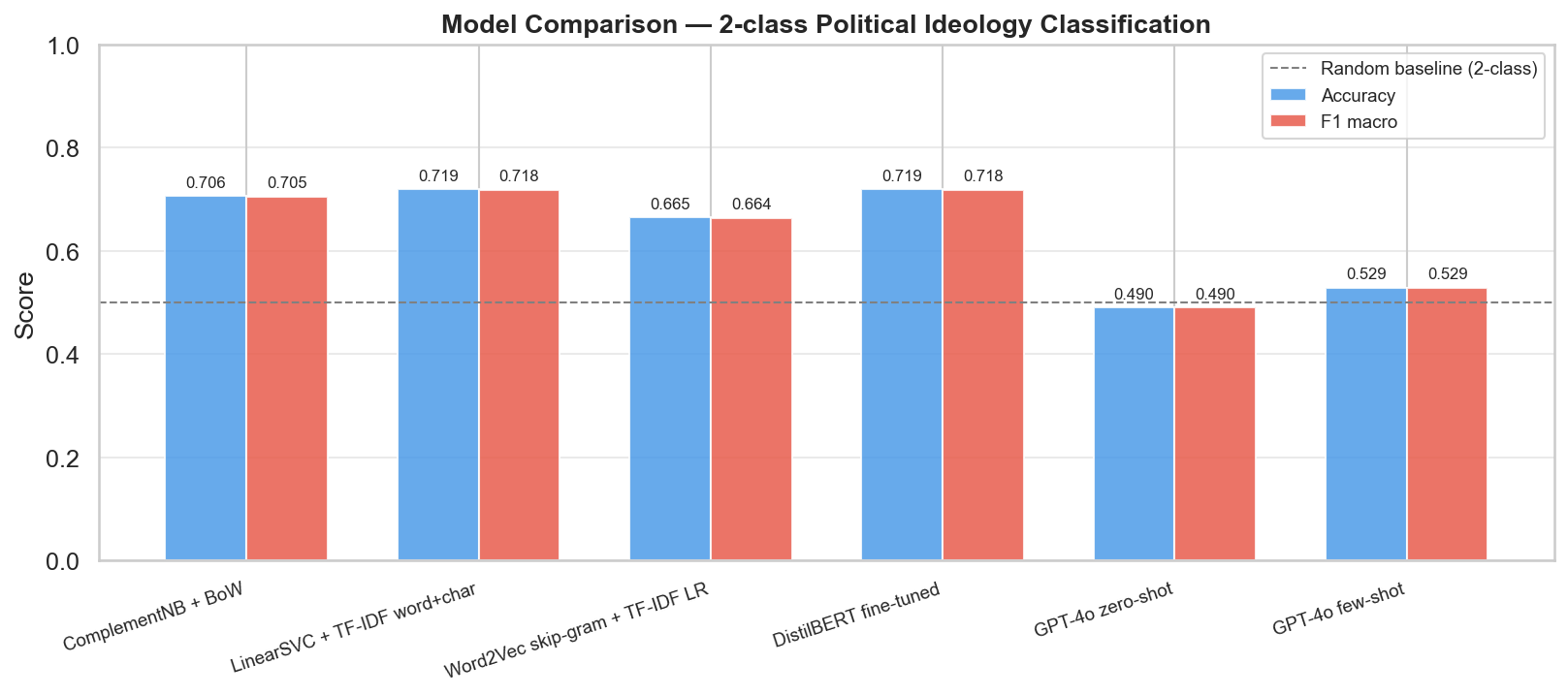
Aggregated F1-macro across all five models. The fine-tuned DistilBERT (0.726) and the TF-IDF LinearSVC (0.718) sit almost level at the top; the zero-shot LLM trails near chance — a compact visual case that more model is not more signal here.
Key findings
- The task is lexical, not compositional. Fine-tuned DistilBERT (0.726) barely edges out a TF-IDF LinearSVC baseline (0.718): polarised commenters use a small high-signal vocabulary (Trump, MAGA, Biden, woke) that n-gram features capture directly, so contextual embeddings add little.
- Cross-channel generalisation drops 12.6 points (0.718 → 0.592) when holding out a whole channel — the model partially learns channel writing style (length, punctuation, register), not pure ideology. Removing host/brand tokens recovers nothing; the residual style signal is irreducible without explicit style normalisation.
- GPT-4o-mini zero-shot ≈ chance (~0.56): without supervision it refuses to commit or hallucinates centrist answers, because the task requires aligning with channel positioning rather than the comment's own ideology.
Method & technology stack
- Data: 301,536 comments from 7 US political channels; two cleaning variants; 80/20 stratified split (seed 42).
- Classical NLP: Bag of Words (Complement Naïve Bayes), TF-IDF with word and character n-grams (LinearSVC), Word2Vec embeddings (Logistic Regression).
- Deep learning: fine-tuned DistilBERT (Hugging Face Transformers, PyTorch).
- LLM baseline: GPT-4o-mini zero- and few-shot prompting.
- Analysis: cross-channel hold-one-out ablation, LDA topic modelling, confusion matrices, top-feature inspection.
- Stack: Python, scikit-learn, Gensim, Hugging Face Transformers, PyTorch, Matplotlib; Google Colab.
Exploratory analysis
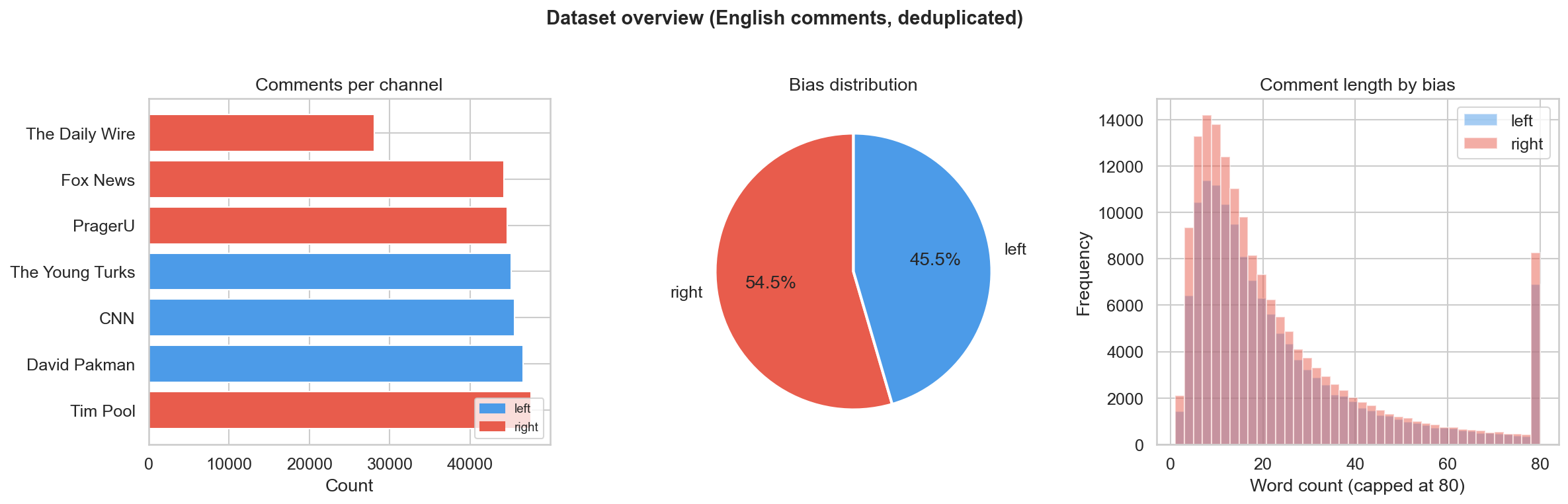
Dataset overview: comment-count balance across the 7 channels and the two ideology classes, plus comment-length distributions — the EDA that motivated stratified splitting and character-level n-grams.
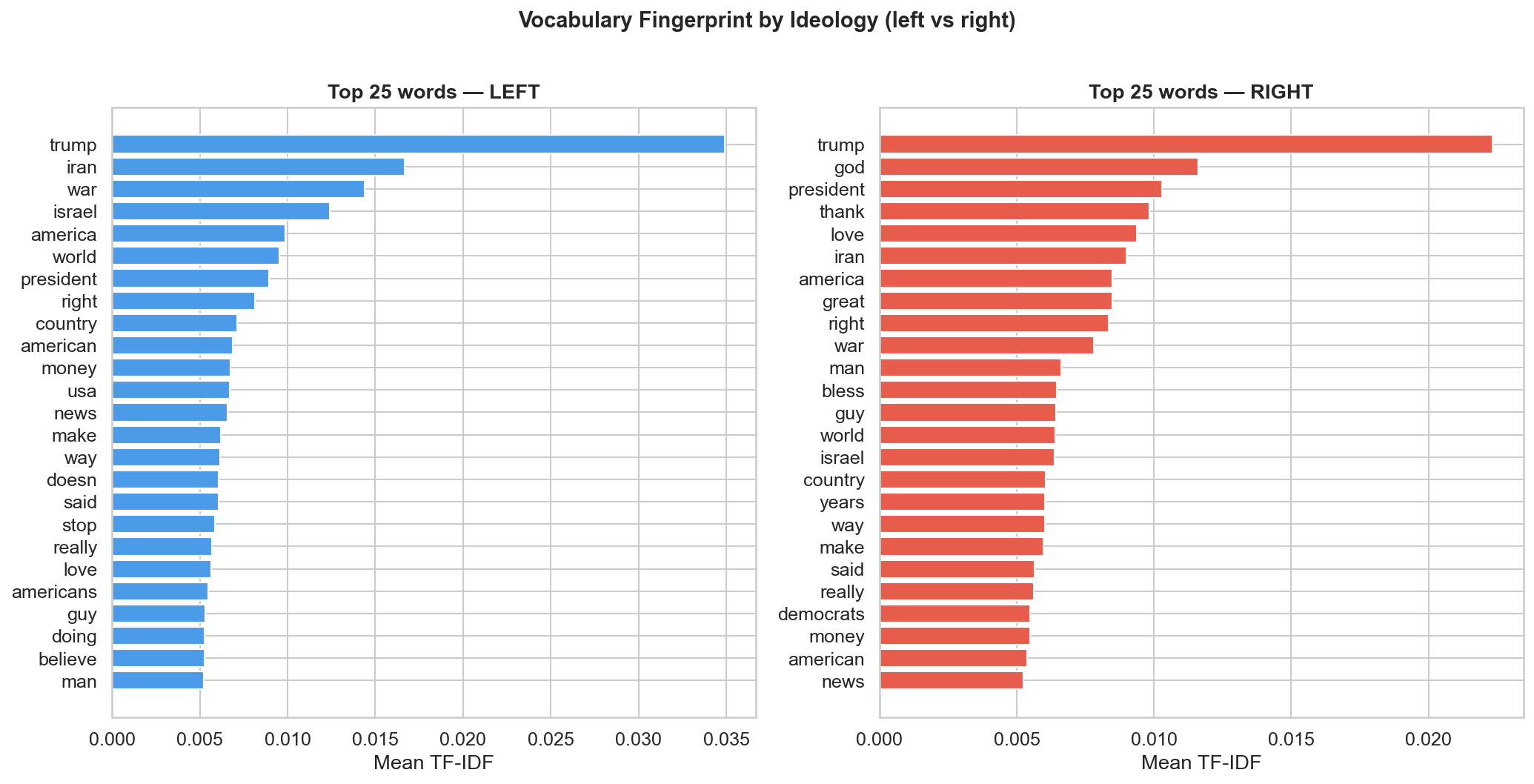
Most distinctive words per ideology. The strongly partisan, low-overlap vocabulary on each side is exactly why simple n-gram models already score in the low-0.7s.
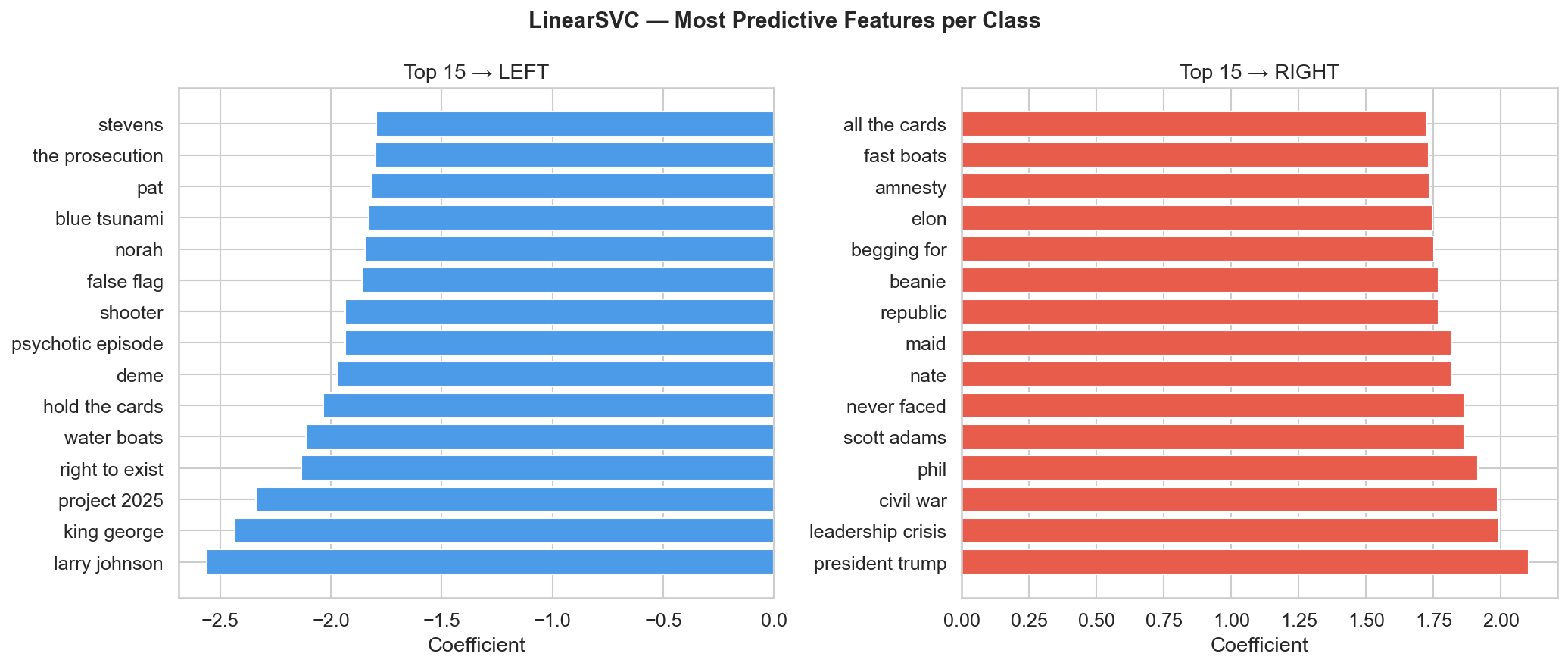
Highest-weight TF-IDF features in the LinearSVC. The model's decisions hinge on a small set of named-entity and slogan tokens — interpretable, and evidence the signal is lexical.
Cross-channel generalisation
The ablation holds out each channel in turn and tests on it — the single most important result. F1 falls from 0.718 to 0.592, a 12.6-point drop, showing the within-channel models partly exploit channel style rather than transferable ideological signal.
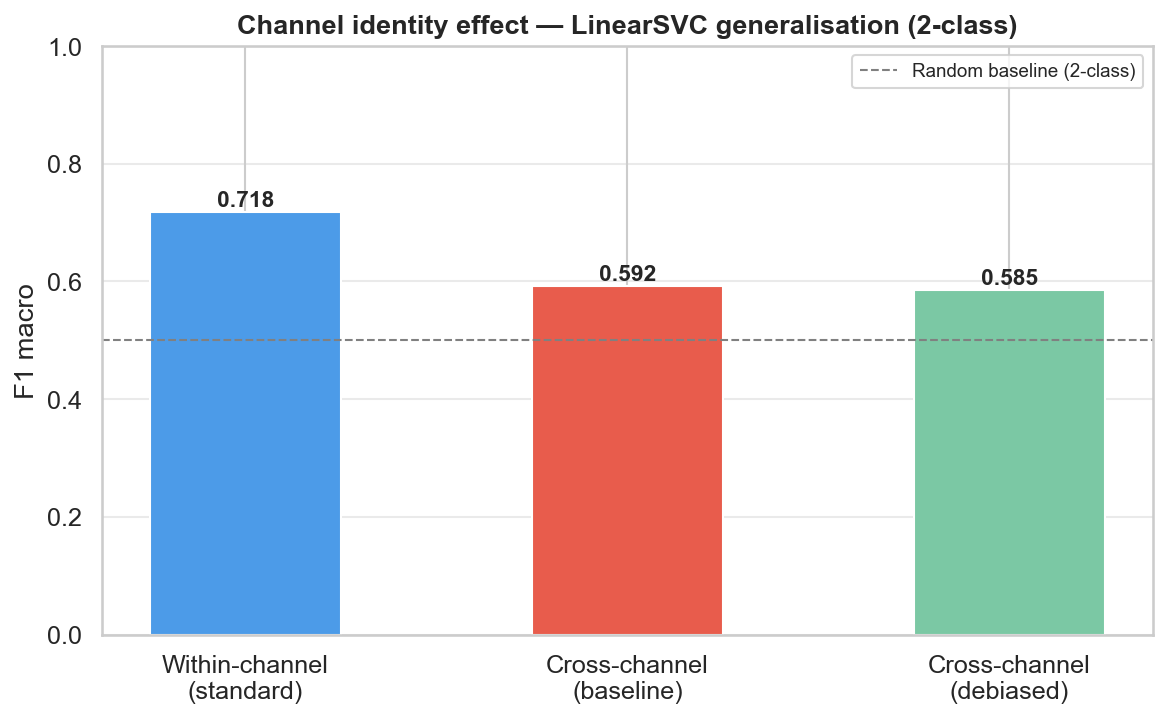
Within-channel vs hold-one-channel-out F1. The consistent gap across held-out channels is the clearest evidence that part of what looks like "ideology detection" is really channel-style detection.
Best model — DistilBERT
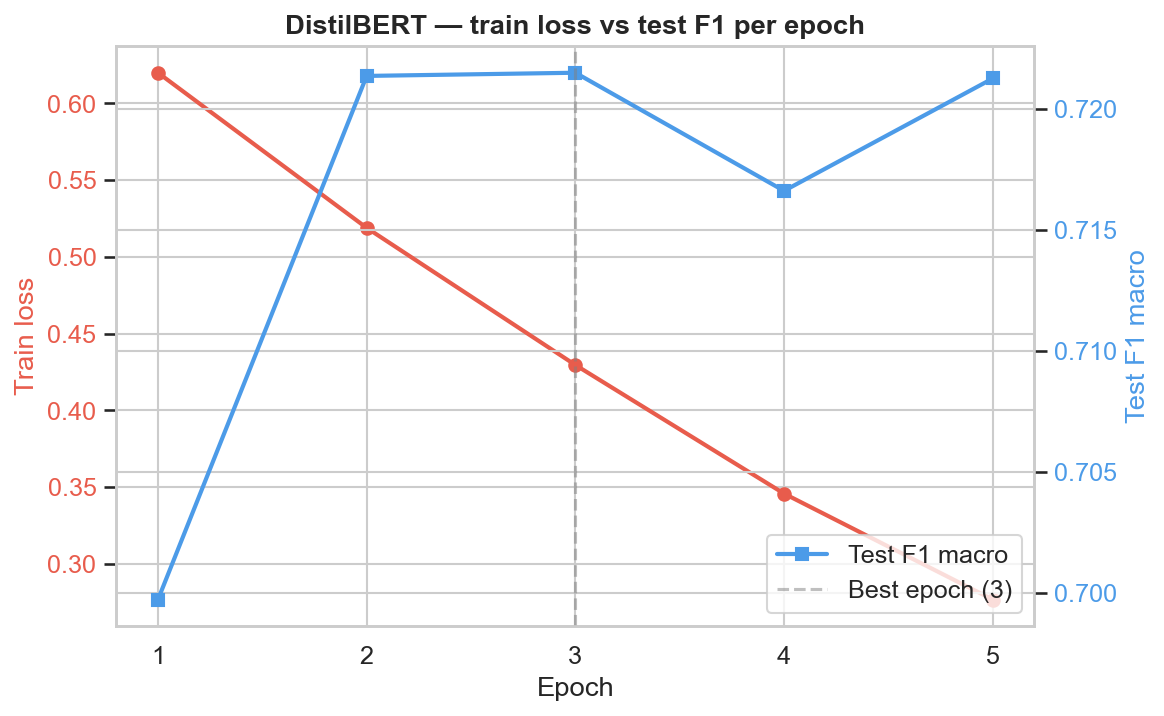
DistilBERT fine-tuning curve: training and validation loss converge smoothly with no runaway overfitting, supporting the reported 0.726 F1.
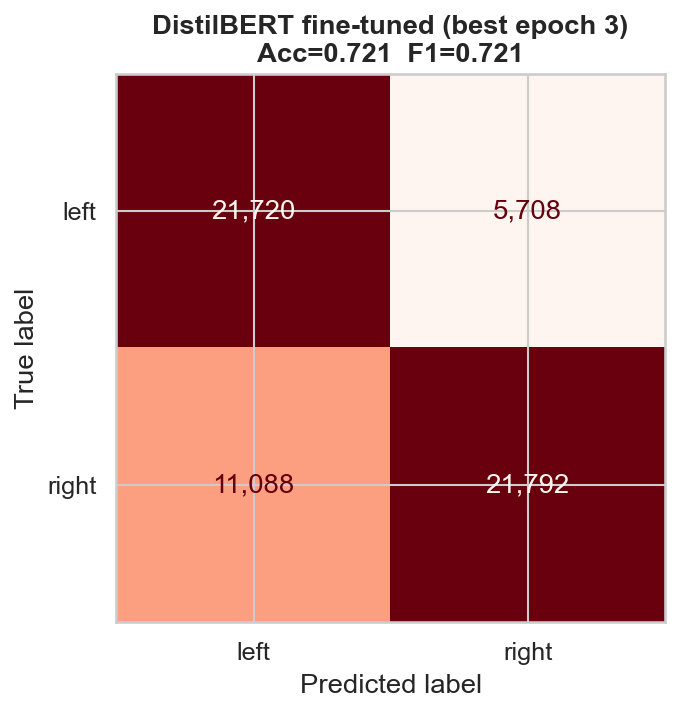
DistilBERT confusion matrix — the one worth showing: errors are near-symmetric between left and right, so the model is balanced rather than biased toward one side.
LDA topic modelling (qualitative bonus): the recovered topics map onto recognisable partisan themes, a sanity check that the corpus carries genuine ideological structure.
Limitations
- Channel-label proxy — every commenter inherits the host channel's ideology, so cross-ideological commenters get mislabelled.
- No cross-channel generalisation — F1 drops from 0.718 to 0.592 on unseen channels.
- DistilBERT best-epoch selection used test F1, giving a minor optimistic bias; a clean train/val/test split would give a lower but cleaner estimate.
AI disclosure
Coding assistance via Claude/ChatGPT (boilerplate scaffolding, debugging, documentation). All modelling decisions, preprocessing logic, label engineering and analytical narrative are the authors'.
Dataset & downloads
Dataset on Hugging Face Final paper (PDF) Notebook (.ipynb) Code on GitHub
Related Projects
- Banana Ripeness Classification — deep learning image classification, CBS Data Science 2026
- Forecasting Danish Pharmaceutical Exports — time-series forecasting, CBS Data Science 2026
- Bachelor Thesis — quantitative statistical modelling in R